

 脸书专页
脸书专页 翻墙交流电报群
翻墙交流电报群信息验证:如何自动反向?#OSINT 技术
小工具,挖信息,提高生产力

如何从 YouTube 视频中获取预览图像并将其用于信息验证?以及找到链接到该视频的其他网站?这种技术称为反向图像搜索——— 对于开源调查 OSINT 来说是非常强大的,因为它可以为您提供额外的站点,可以查看谁正在使用特定的视频,并且它还可以告诉您是否有人在制作原始视频时撒了谎。
我们现在要做的是使用 YouTube API 和 TinEye API(付费)自动完成此过程。本练习的目的是开发一个脚本,只需输入 YouTube 视频 ID,让脚本检索视频缩略图并将其提交给 TinEye 进行反向图像搜索。这里的目标是加快进行此验证的过程。
YouTube API——检索预览照片
YouTube API 非常适合搜索视频以及从视频记录中提取大量元数据。我们将利用 API 检索特定视频的缩略图,然后将这些缩略图传递给 TinEye API,以便让它帮助执行反向图像搜索。
首先,请务必在此处获取 YouTube API 密钥。此外,还有一种已知的 URL 格式,可以为您提供额外的视频预览图像。我们将在脚本中构建此 URL 格式,以便获得最佳覆盖率。
TinEye API
TinEye 的人很友好,还创建了一个 Python 库,用于与他们的商业 API 进行通信。您可以从这里获取它,文档在这里。请确保按照他们的说明安装 Python 库。
开始编码
首先,
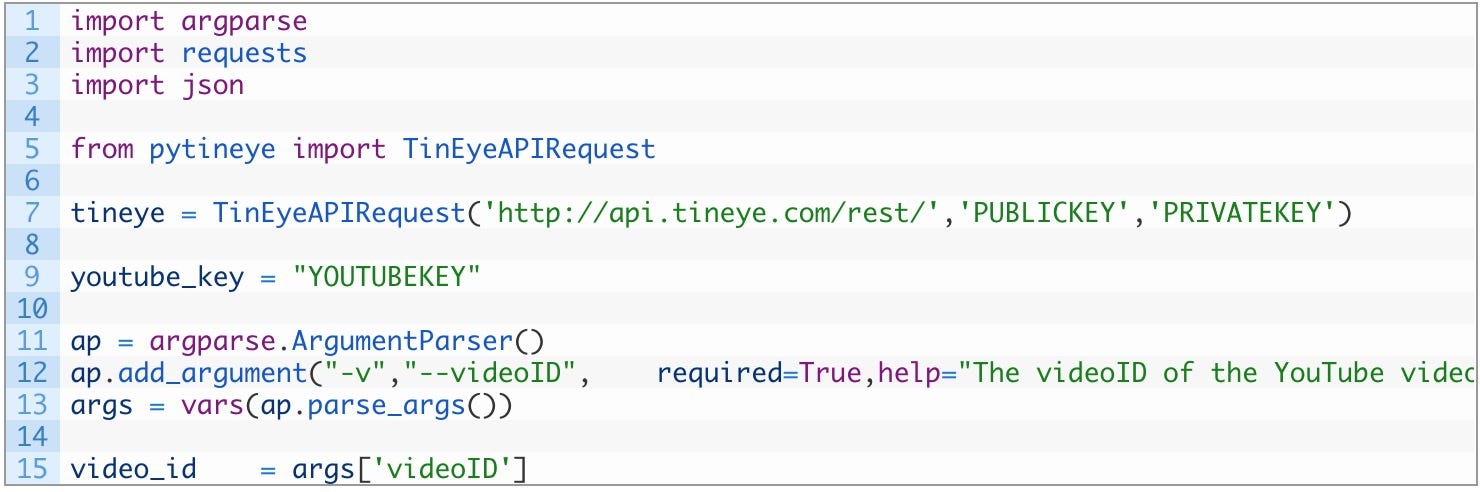
这里只是介绍必要的库,初始化 TinEye API 并添加一些命令行参数解析。没有什么太花哨的。现在进入 YouTube API 调用的管道:
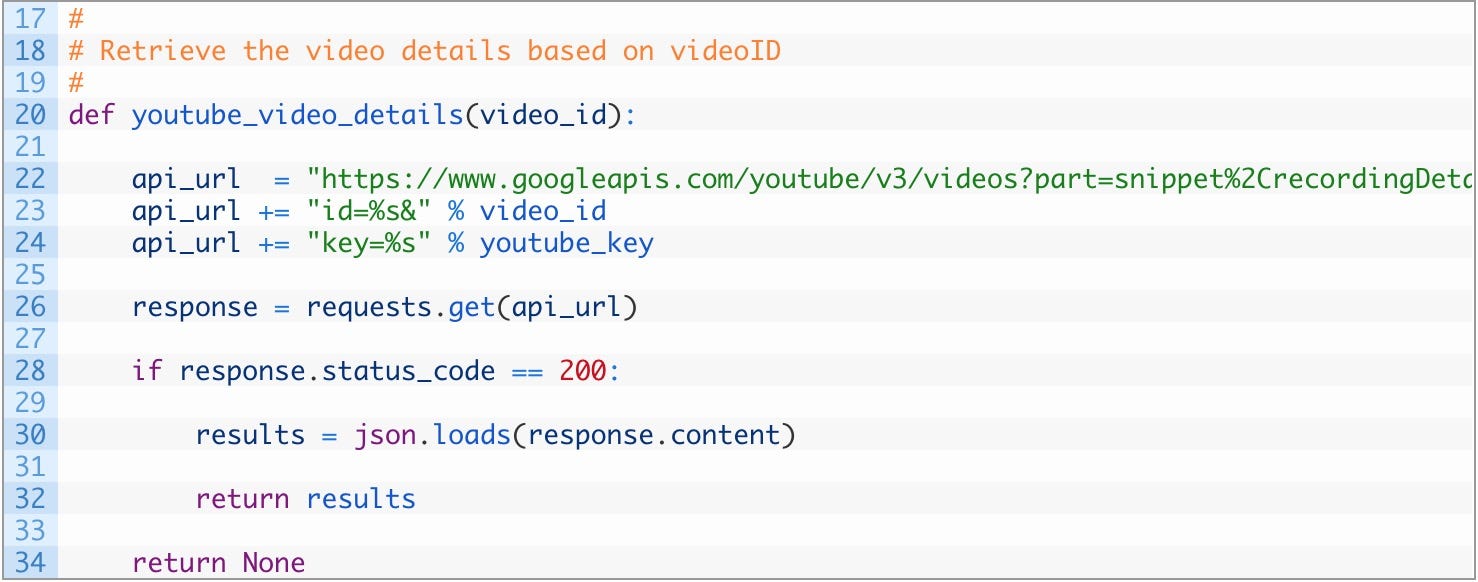
好的,再解释一下:
- 第 20 行: 正在定义 youtube_video_details 函数以获取视频 ID。
- 第 22–24 行: 通过传递视频 ID 和 YouTube API 密钥来构建我们的 YouTube API 请求网址。
- 第 26 行: 将请求发送到 Google 服务器。
- 第 28–32 行: 如果我们得到一个好的响应(28)解析 JSON(30)并返回查询结果(32)。
完美,此功能将用于获取与每个 YouTube 视频相关联的默认缩略图。现在将使用此函数构建一个可以传递给 TinEye 的图像 URL 列表。我们现在添加这样的代码:
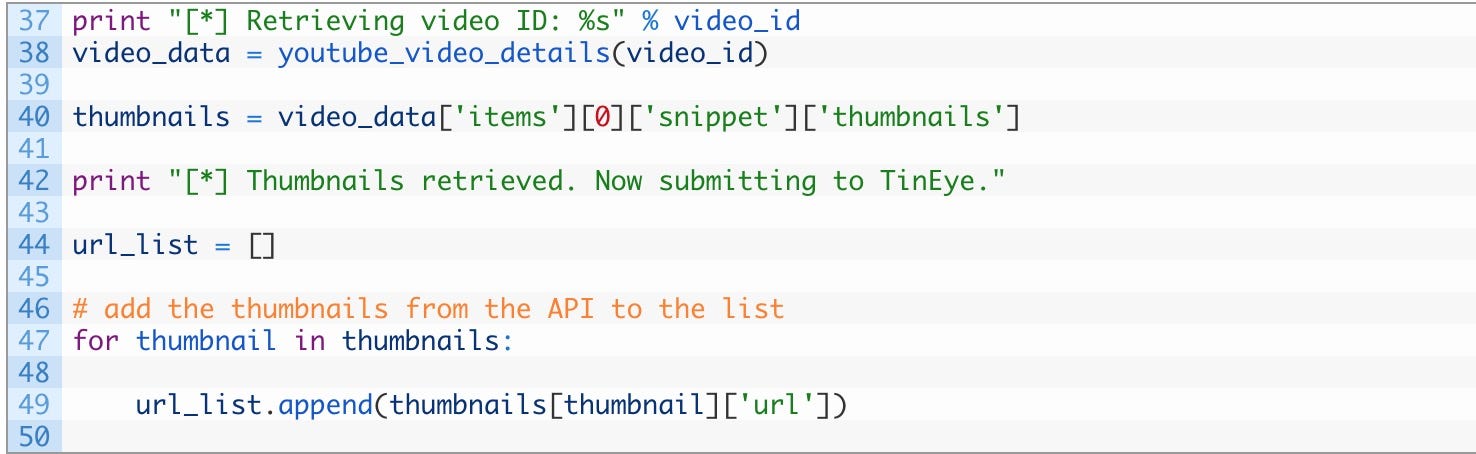
- 第 38 行: 使用之前开发的函数来检索与特定视频相关的所有数据(请注意:您可以浏览 video_data 变量并查看附加到每个视频的所有元数据)。
- 第 40 行: 从结果中提取缩略图列表。
- 第 47–49 行: 在这里循环每个缩略图(47)并将其添加到 URL 的主列表(49)。稍后将使用此主列表。
现在有了一个众所周知但未被记录过的 YouTube 视频技巧,可让您为感兴趣的视频获取额外的预览图像。这只是简单地在 YouTube 服务器上采用已知路径,以及视频 ID 和请求顺序图像列表。添加以下代码来实现此目的:

非常简单,只需运行从 0 到 3 的循环计数,并使用计数器和我们传入脚本的视频 ID 构建 URL。所以这将生成一个列表,这样:
http://img.youtube.com/vi/zGM47VtGQ-4/0.jpg
http://img.youtube.com/vi/zGM47VtGQ-4/1.jpg
http://img.youtube.com/vi/zGM47VtGQ-4/2.jpg
http://img.youtube.com/vi/zGM47VtGQ-4/3.jpg
现在我们将遍历每个 URL 并将其提交给 TinEye API。敲以下代码:
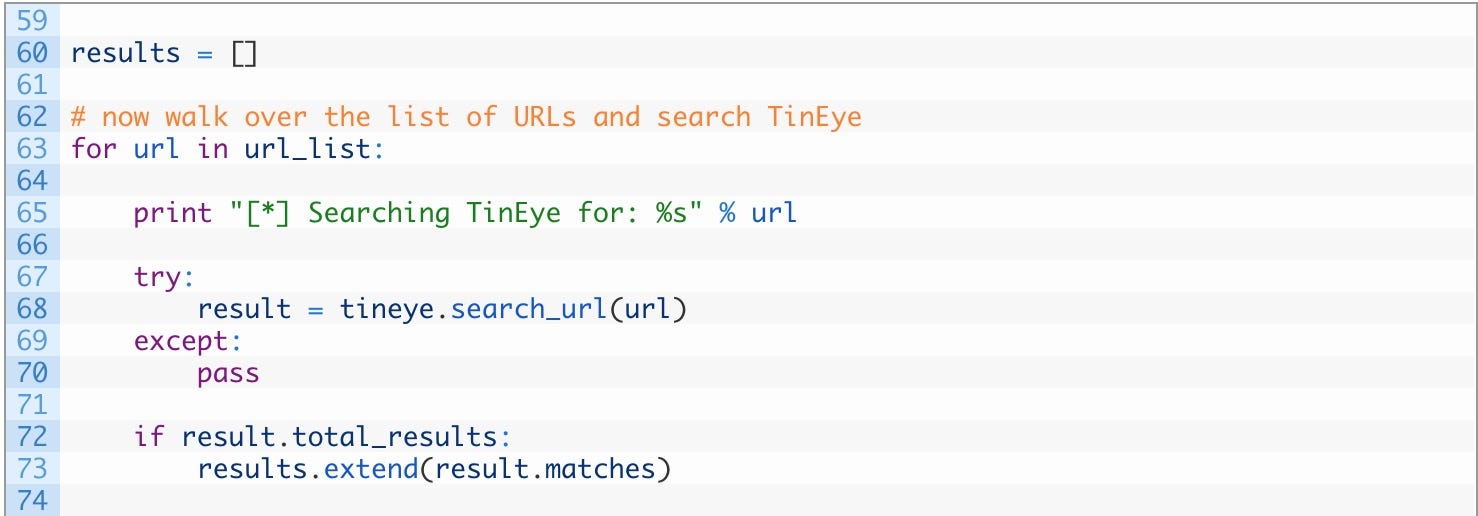
- 第 60 行: 初始化一个结果列表,将存储从 TinEye 返回的所有匹配项。
- 第 63–73 行: 遍历我们的 URL 列表(63)然后使用 search_url 函数(68)将 URL 提交给 TinEye API 。如果检测到匹配(72)将每个匹配添加到 results 列表中(73)。
好的,此时应该有一个 TinEye Match 对象列表,其中包含有关搜索结果的信息。现在选择该对象,并提取重要的信息,即该图像的任何匹配网站的 URL 以及 TinEye 抓取它的日期。

- 第 75–76 行: 初始化 result_urls 列表(75)以存储在 TinEye 索引中找到的任何 URL 和一个 日期 字典,该字典将保存按日期键入的 URL,以便对它们进行排序,并确定包含匹配图像的最早日子的网址。
- 第 78–85 行: 遍历每个匹配(78)然后开始循环遍历 TinEye Match 对象(80)中包含的每个链接。测试一下是否已经捕获了 URL(82)如果没有存储 URL(84)和它已被检索的日期(85)。
很棒,完成了!只需要下面这一点:

非常简单的东西。只是循环遍历所有发现的网址并将其打印出来。然后通过对日期进行排序并使用最早的 date 作为 dictionary 中的 Key 来查找。
这里有一个关于在叙利亚从地面发射火箭的视频,用它来测试一下。该视频位于:www.youtube.com/watch?v=zGM47VtGQ-4
因此,要使用的视频 ID 是:zGM47VtGQ-4
justin$:> python bellingcatyoutube.py -v zGM47VtGQ-4
[*] Retrieving video ID: zGM47VtGQ-4
[*] Thumbnails retrieved. Now submitting to TinEye.
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/default.jpg
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/hqdefault.jpg
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/mqdefault.jpg
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/maxresdefault.jpg
[*] Searching TinEye for: https://i.ytimg.com/vi/zGM47VtGQ-4/sddefault.jpg
[*] Searching TinEye for: http://img.youtube.com/vi/zGM47VtGQ-4/0.jpg
[*] Searching TinEye for: http://img.youtube.com/vi/zGM47VtGQ-4/1.jpg
[*] Searching TinEye for: http://img.youtube.com/vi/zGM47VtGQ-4/2.jpg
[*] Searching TinEye for: http://img.youtube.com/vi/zGM47VtGQ-4/3.jpg
[*] Discovered 725 unique URLs with image matches.
http://nnm.me/blogs/Y2k_live/chto-mogut-protivopostavit-boeviki-igil-rossiyskim-samoletam/
http://edition.cnn.com/2014/11/12/world/meast/syria-isis-child-fighter/index.html
http://www.cnn.com/2014/11/12/world/meast/syria-isis-child-fighter/index.html
http://www.cnn.com/2014/11/14/world/meast/isis-setbacks-iraq-lister/
http://www.tinmoi.vn/thach-thuc-tag.html
http://finance.chinanews.com/stock/2013/10-11/5364352.shtml
….
[*] Oldest match was crawled on 2014–10–10 00:00:00 at http://finance.chinanews.com/stock/2013/11-15/5508881.shtml
很棒啊,所以现在你可能有很多网站可以去调查。如果要验证正在观看的镜头是新的还是旧的,被抓取的最早日期是非常重要的。过程可能由于 TinEye index 的不同而不同。
自动反向图像搜索第 2 部分:Vimeo
Vimeo Simple API
Vimeo 确实有一个全功能的 API,可以用它来做各种奇特的东西,如搜索视频、用户等。这称为高级 API。但是 Vimeo 还有一个方便的功能,它们会自动为他们发布的每个视频提供 JSON 输出,他们称之为 Simple API。例如,这个排球视频:
我们可以看到该视频的视频 ID 是:71215064
要检索此视频的所有 JSON,我们可以使用以下 URL 方案:
http://vimeo.com/api/v2/video/{VIDEOID}.json
所以在排球示例中,看起来像这样:
http://vimeo.com/api/v2/video/71215064.json
使用 Simple API 的主要缺点是它仅对公共视频有用。如果您需要脚本查询私有视频或对 Vimeo 进行更高级的查询,则需要获取 API 密钥并查看开发人员文档。
检查 JSON
那么这个 JSON 文档实际上包含什么?如果您只是浏览到该 URL,浏览器将下载一个 JSON 文件,您可以使用喜欢的文本编辑器或我最喜欢的 Python IDE,Wing 打开它。我们来看看JSON:
u’duration’: 303,
u’embed_privacy’: u’anywhere’,
u’height’: 480,
u’id’: 71215064,
u’mobile_url’: u’https://vimeo.com/71215064′,
u’stats_number_of_comments’: 3,
u’stats_number_of_likes’: 59,
u’stats_number_of_plays’: 49593,
u’tags’: u’volleyball, olympics, olympic games, london 2012, highlights, slow motion, brazil, russia, poland, italy’,
u’thumbnail_large’: u’https://i.vimeocdn.com/video/444712440_640.webp’,
u’thumbnail_medium’: u’https://i.vimeocdn.com/video/444712440_200x150.webp’,
u’thumbnail_small’: u’https://i.vimeocdn.com/video/444712440_100x75.webp’,
u’title’: u’Olympic Games 2012 Volleyball in slow motion’,
u’upload_date’: u’2013–07–28 17:34:09′,
u’url’: u’https://vimeo.com/71215064′,
u’user_id’: 2460313,
u’user_name’: u’Yngve Sundfjord’,
u’user_portrait_huge’: u’https://i.vimeocdn.com/portrait/362408_300x300.webp’,
u’user_portrait_large’: u’https://i.vimeocdn.com/portrait/362408_100x100.webp’,
u’user_portrait_medium’: u’https://i.vimeocdn.com/portrait/362408_75x75.webp’,
u’user_portrait_small’: u’https://i.vimeocdn.com/portrait/362408_30x30.webp’,
u’user_url’: u’https://vimeo.com/sundfjord’,
u’width’: 640}]
很棒吧,在这里存储了大量有用的信息。特别是如果你对 thumbnail_large 密钥感兴趣,因为这将为你提供可用于提交给 TinEye API 的图像,以查看是否有其他结果或包含目标图像的其他网站。同样,你会注意到 upload_date ,可以使用它来验证此视频是否在反向图像搜索中找到的其他结果之前出现过。
开始编码。打开一个新脚本并将其命名为 vimeoreversesearch.py 并打入以下代码:

没有什么太花哨的。只是设置 TinEye API,为脚本添加一些参数解析,并从传入的命令行参数中提取 video_id 变量。现在实现我们的 Vimeo JSON 检索功能:
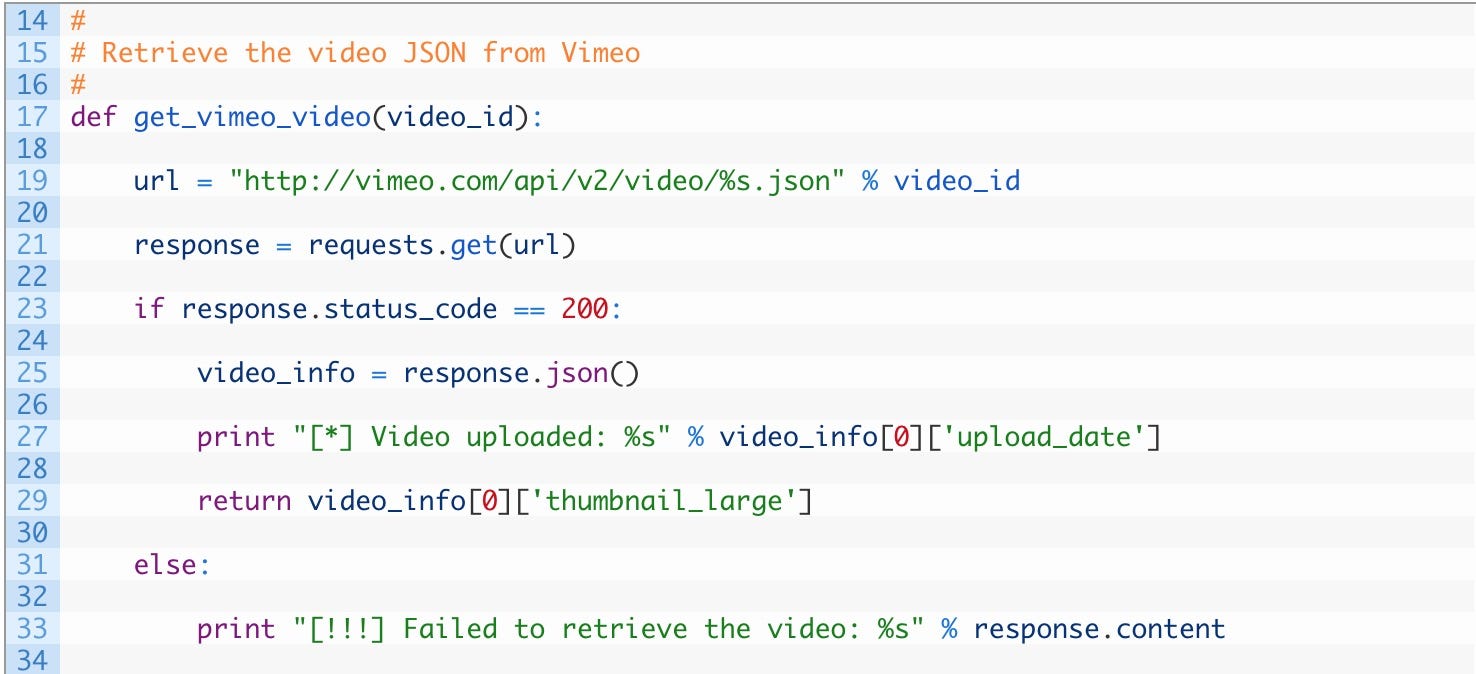
- 第 17 行: 定义了 get_vimeo_video 函数,该函数接收一个 video_id 参数,该参数表示我们之前介绍过的 Vimeo 视频 ID。
- 第 19–21 行: 正在构建 URL 以检索视频 JSON(19),然后关闭 HTTP 请求(21)。
- 第 23–29 行: 如果我们的请求成功(23)那么将解析的 JSON 存储在 video_info 变量中(25)。输出视频上传的日期(27)然后返回视频的大预览图像的位置(29)。
好的,到目前为止开发的代码将负责从 Vimeo 服务器中获取和解析 JSON,并为我们提供一个图像位置,可以用它来使用 TinEye API 进行反向搜索。现在通过实现一个处理它的函数将该图像传送给 TinEye。其中一些代码可以从之前的帖子中重复过来,因此看起来很熟悉。将以下代码添加到脚本中:
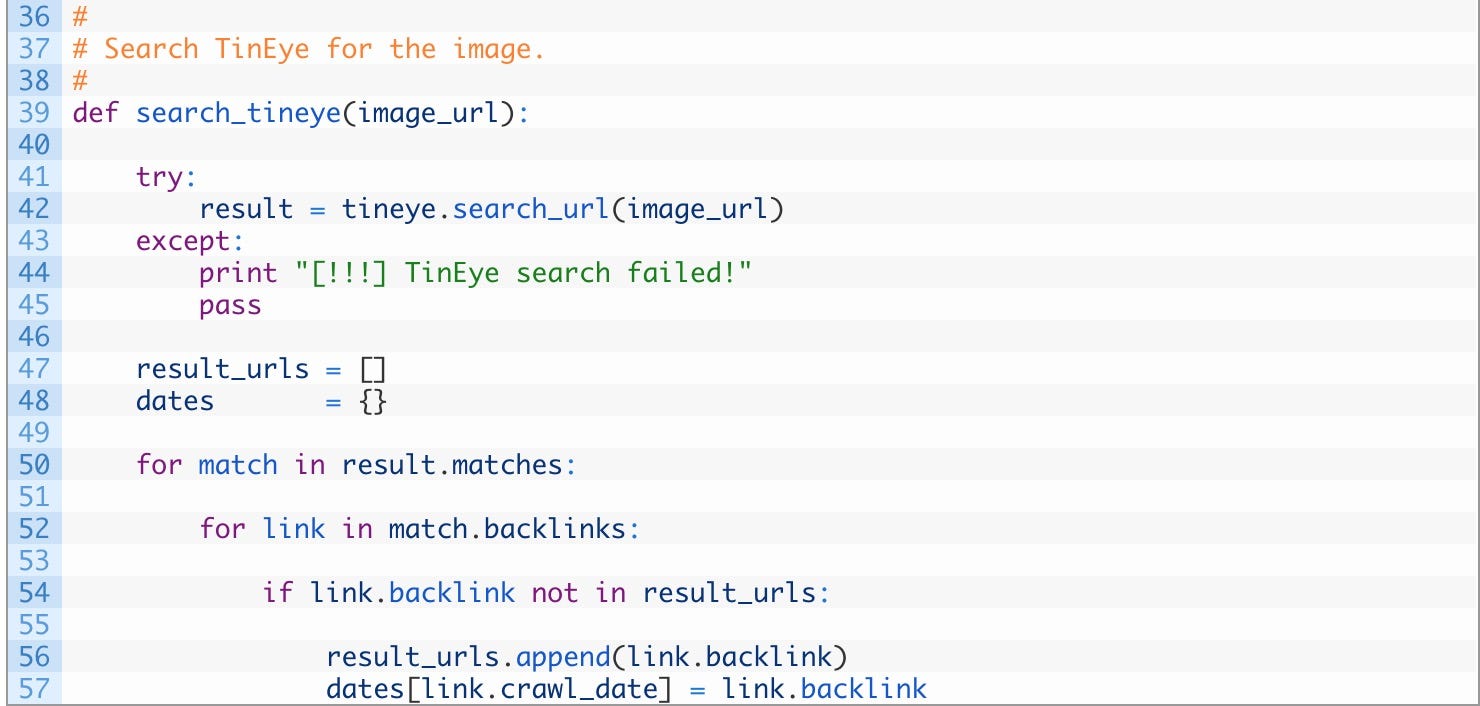
- 第 39 行: 创建 search_tineye 函数,该函数接收 image_url 参数,该参数是 Vimeo 预览图像的位置。
- 第 41–45 行: 将请求发送到 TinEye API(42),如果我们的调用有任何问题(通常是因为您错误地复制/粘贴了 API 密钥),那么输出一条错误消息(44)并返回( 45)。
- 第 50–57 行: 浏览 TinEye 结果列表(50),每个结果可以包含已跑过的 links(52)。开始向 result_urls 添加新链接(56)并将链接日期添加到日期列表中,以便稍后可以找到最早出现的帖子。
现在实现将向我们展示 API 请求结果的部分。添加以下代码:
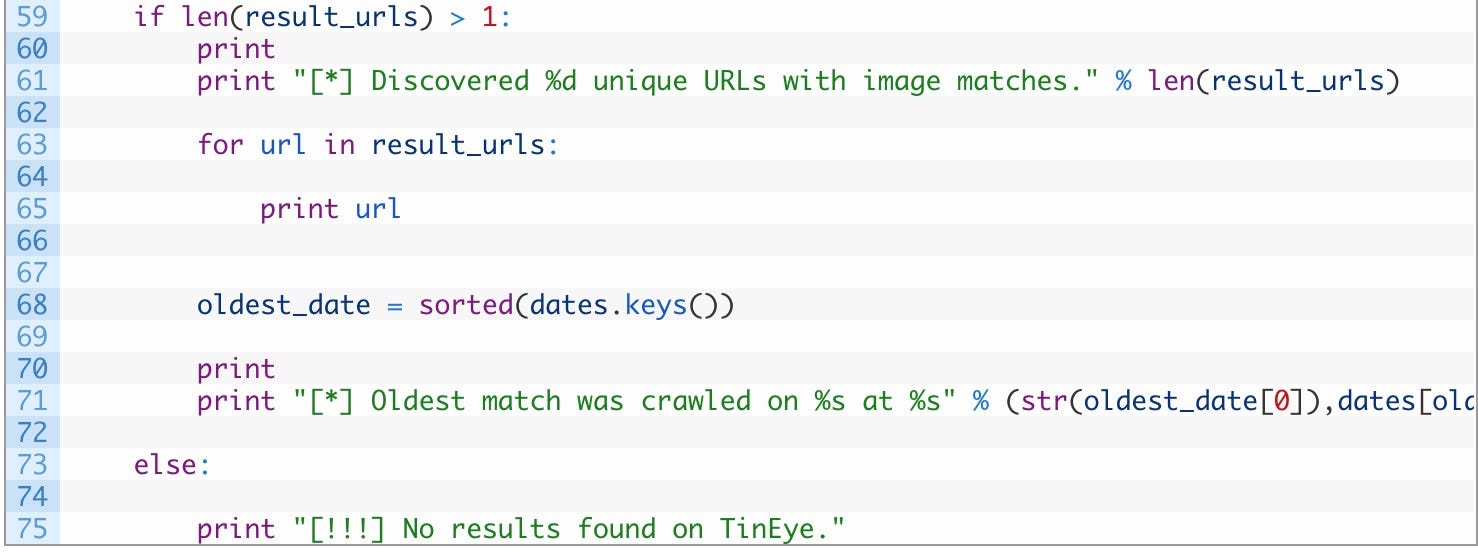
- 第 59 行: 在这里测试 result_urls 列表中是否有项目表明我们的 TinEye 请求有点击。
- 第 60–65 行: 打印出命中数(61)然后遍历结果列表(63)并打印出找到图像的URL(65)。
- 第 68–71 行: 对日期列表(68)进行排序,这将按时间顺序排列,这样我们就可以打印出最早的日期了(71)。
好了大部分脚本已经完成,所以现在需要做的就是调用我们设置的函数:

当您使用上面的 ID 运行脚本时,它将如下所示:
# python vimeo_reverse_search.py -v 71215064
[*] Video uploaded: 2013–07–28 17:34:09
[*] Discovered 2 unique URLs with image matches.
[*] Oldest match was crawled on 2014–02–07 00:00:00 at http://wn.com/Olympic_Games
很酷,所以可以看到视频已于 2013 年7月28日上传,我们发现最早检测到的图像是从 2014年2月7日开始的。这可能表明 Vimeo 上的视频在被检测之前已经在其他网站上线了。如果发布者声称这是一条新闻,那么他很可能在做假。
当记者不专业的时候你也可以指出他们的错误,有理有据。
感谢帮助 iYouPort!PayPal 捐赠渠道已开通 https://paypal.me/iyouport
